

Gemma 2 builds upon its predecessor, offering enhanced performance and efficiency, along with a suite of innovative features that make it particularly appealing for both research and practical applications. What sets Gemma 2 apart is its ability to deliver performance comparable to much larger proprietary models, but in a package that’s designed for broader accessibility and use on more modest hardware setups.
As I delved into the technical specifications and architecture of Gemma 2, I found myself increasingly impressed by the ingenuity of its design. The model incorporates several advanced techniques, including novel attention mechanisms and innovative approaches to training stability, which contribute to its remarkable capabilities.
In this comprehensive guide, we’ll explore Gemma 2 in depth, examining its architecture, key features, and practical applications. Whether you’re a seasoned AI practitioner or an enthusiastic newcomer to the field, this article aims to provide valuable insights into how Gemma 2 works and how you can leverage its power in your own projects.
What is Gemma 2?
Gemma 2 is Google’s newest open-source large language model, designed to be lightweight yet powerful. It’s built on the same research and technology used to create Google’s Gemini models, offering state-of-the-art performance in a more accessible package. Gemma 2 comes in two sizes:
Gemma 2 9B: A 9 billion parameter model
Gemma 2 27B: A larger 27 billion parameter model
Each size is available in two variants:
Base models: Pre-trained on a vast corpus of text data
Instruction-tuned (IT) models: Fine-tuned for better performance on specific tasks
Access the models in Google AI Studio: Google AI Studio – Gemma 2
Read the paper here: Gemma 2 Technical Report
Key Features and Improvements
Gemma 2 introduces several significant advancements over its predecessor:
1. Increased Training Data
The models have been trained on substantially more data:
Gemma 2 27B: Trained on 13 trillion tokens
Gemma 2 9B: Trained on 8 trillion tokens
This expanded dataset, primarily consisting of web data (mostly English), code, and mathematics, contributes to the models’ improved performance and versatility.
2. Sliding Window Attention
Gemma 2 implements a novel approach to attention mechanisms:
Every other layer uses a sliding window attention with a local context of 4096 tokens
Alternating layers employ full quadratic global attention across the entire 8192 token context
This hybrid approach aims to balance efficiency with the ability to capture long-range dependencies in the input.
3. Soft-Capping
To improve training stability and performance, Gemma 2 introduces a soft-capping mechanism:
def soft_cap(x, cap):
return cap * torch.tanh(x / cap)
# Applied to attention logits
attention_logits = soft_cap(attention_logits, cap=50.0)
# Applied to final layer logits
final_logits = soft_cap(final_logits, cap=30.0)
This technique prevents logits from growing excessively large without hard truncation, maintaining more information while stabilizing the training process.
- Gemma 2 9B: A 9 billion parameter model
- Gemma 2 27B: A larger 27 billion parameter model
Each size is available in two variants:
- Base models: Pre-trained on a vast corpus of text data
- Instruction-tuned (IT) models: Fine-tuned for better performance on specific tasks
4. Knowledge Distillation
For the 9B model, Gemma 2 employs knowledge distillation techniques:
- Pre-training: The 9B model learns from a larger teacher model during initial training
- Post-training: Both 9B and 27B models use on-policy distillation to refine their performance
This process helps the smaller model capture the capabilities of larger models more effectively.
5. Model Merging
Gemma 2 utilizes a novel model merging technique called Warp, which combines multiple models in three stages:
- Exponential Moving Average (EMA) during reinforcement learning fine-tuning
- Spherical Linear intERPolation (SLERP) after fine-tuning multiple policies
- Linear Interpolation Towards Initialization (LITI) as a final step
This approach aims to create a more robust and capable final model.
Performance Benchmarks
Gemma 2 demonstrates impressive performance across various benchmarks:
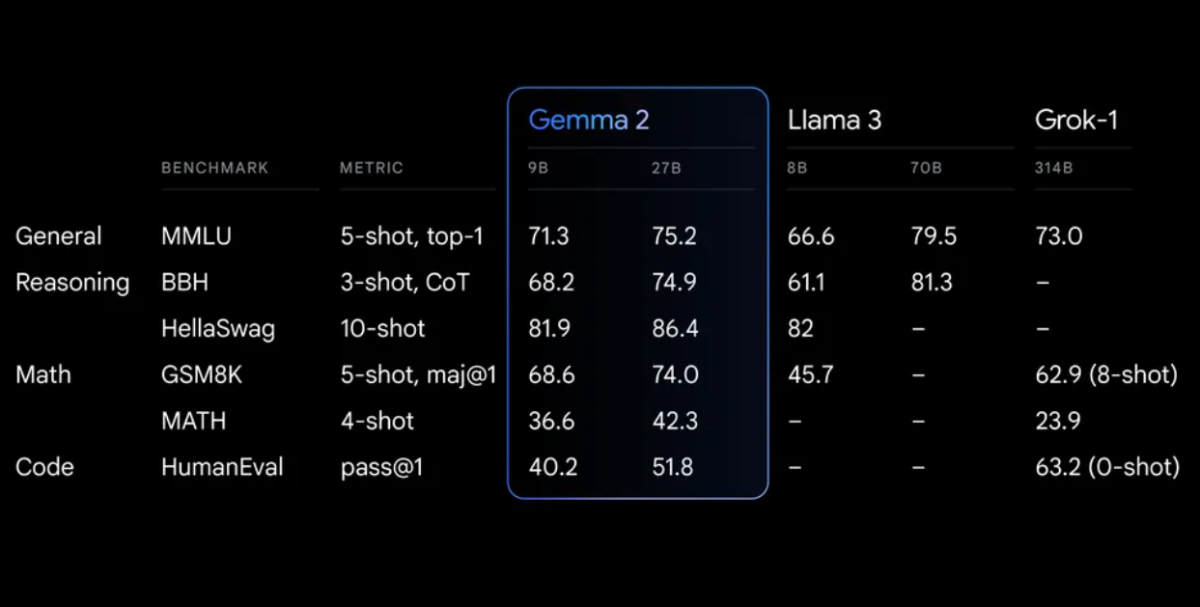
Gemma 2 on a redesigned architecture, engineered for both exceptional performance and inference efficiency
Getting Started with Gemma 2
To start using Gemma 2 in your projects, you have several options:
1. Google AI Studio
For quick experimentation without hardware requirements, you can access Gemma 2 through Google AI Studio.
2. Hugging Face Transformers
Gemma 2 is integrated with the popular Hugging Face Transformers library. Here’s how you can use it:
<div class="relative flex flex-col rounded-lg"> <div class="text-text-300 absolute pl-3 pt-2.5 text-xs"> from transformers import AutoTokenizer, AutoModelForCausalLM # Load the model and tokenizer model_name = "google/gemma-2-27b-it" # or "google/gemma-2-9b-it" for the smaller version tokenizer = AutoTokenizer.from_pretrained(model_name) model = AutoModelForCausalLM.from_pretrained(model_name) # Prepare input prompt = "Explain the concept of quantum entanglement in simple terms." inputs = tokenizer(prompt, return_tensors="pt") # Generate text outputs = model.generate(**inputs, max_length=200) response = tokenizer.decode(outputs[0], skip_special_tokens=True) print(response)
3. TensorFlow/Keras
For TensorFlow users, Gemma 2 is available through Keras:
import tensorflow as tf
from keras_nlp.models import GemmaCausalLM
# Load the model
model = GemmaCausalLM.from_preset("gemma_2b_en")
# Generate text
prompt = "Explain the concept of quantum entanglement in simple terms."
output = model.generate(prompt, max_length=200)
print(output)
Advanced Usage: Building a Local RAG System with Gemma 2
One powerful application of Gemma 2 is in building a Retrieval Augmented Generation (RAG) system. Let’s create a simple, fully local RAG system using Gemma 2 and Nomic embeddings.
Step 1: Setting up the Environment
First, ensure you have the necessary libraries installed:
pip install langchain ollama nomic chromadb
Step 2: Indexing Documents
Create an indexer to process your documents:
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import DirectoryLoader
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
class Indexer:
def __init__(self, directory_path):
self.directory_path = directory_path
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
self.embeddings = HuggingFaceEmbeddings(model_name="nomic-ai/nomic-embed-text-v1")
def load_and_split_documents(self):
loader = DirectoryLoader(self.directory_path, glob="**/*.txt")
documents = loader.load()
return self.text_splitter.split_documents(documents)
def create_vector_store(self, documents):
return Chroma.from_documents(documents, self.embeddings, persist_directory="./chroma_db")
def index(self):
documents = self.load_and_split_documents()
vector_store = self.create_vector_store(documents)
vector_store.persist()
return vector_store
# Usage
indexer = Indexer("path/to/your/documents")
vector_store = indexer.index()
Step 3: Setting up the RAG System
Now, let’s create the RAG system using Gemma 2:
from langchain.llms import Ollama
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
class RAGSystem:
def __init__(self, vector_store):
self.vector_store = vector_store
self.llm = Ollama(model="gemma2:9b")
self.retriever = self.vector_store.as_retriever(search_kwargs={"k": 3})
self.template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Answer: """
self.qa_prompt = PromptTemplate(
template=self.template, input_variables=["context", "question"]
)
self.qa_chain = RetrievalQA.from_chain_type(
llm=self.llm,
chain_type="stuff",
retriever=self.retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": self.qa_prompt}
)
def query(self, question):
return self.qa_chain({"query": question})
# Usage
rag_system = RAGSystem(vector_store)
response = rag_system.query("What is the capital of France?")
print(response["result"])
This RAG system uses Gemma 2 through Ollama for the language model, and Nomic embeddings for document retrieval. It allows you to ask questions based on the indexed documents, providing answers with context from the relevant sources.
Fine-tuning Gemma 2
For specific tasks or domains, you might want to fine-tune Gemma 2. Here’s a basic example using the Hugging Face Transformers library:
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
from datasets import load_dataset
# Load model and tokenizer
model_name = "google/gemma-2-9b-it"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
# Prepare dataset
dataset = load_dataset("your_dataset")
def tokenize_function(examples):
return tokenizer(examples["text"], padding="max_length", truncation=True)
tokenized_datasets = dataset.map(tokenize_function, batched=True)
# Set up training arguments
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=4,
per_device_eval_batch_size=4,
warmup_steps=500,
weight_decay=0.01,
logging_dir="./logs",
)
# Initialize Trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)
# Start fine-tuning
trainer.train()
# Save the fine-tuned model
model.save_pretrained("./fine_tuned_gemma2")
tokenizer.save_pretrained("./fine_tuned_gemma2")
Remember to adjust the training parameters based on your specific requirements and computational resources.
Ethical Considerations and Limitations
While Gemma 2 offers impressive capabilities, it’s crucial to be aware of its limitations and ethical considerations:
- Bias: Like all language models, Gemma 2 may reflect biases present in its training data. Always critically evaluate its outputs.
- Factual Accuracy: While highly capable, Gemma 2 can sometimes generate incorrect or inconsistent information. Verify important facts from reliable sources.
- Context Length: Gemma 2 has a context length of 8192 tokens. For longer documents or conversations, you may need to implement strategies to manage context effectively.
- Computational Resources: Especially for the 27B model, significant computational resources may be required for efficient inference and fine-tuning.
- Responsible Use: Adhere to Google’s Responsible AI practices and ensure your use of Gemma 2 aligns with ethical AI principles.
Conclusion
Gemma 2 advanced features like sliding window attention, soft-capping, and novel model merging techniques make it a powerful tool for a wide range of natural language processing tasks.
By leveraging Gemma 2 in your projects, whether through simple inference, complex RAG systems, or fine-tuned models for specific domains, you can tap into the power of SOTA AI while maintaining control over your data and processes.

